I strongly recommend reading the previous blog post before diving deep into this one.
Problems with Hackney
When it comes to HTTP clients in Elixir the first option would be HTTPoison. HTTPoison is a wrapper around Erlang HTTP client called hackney. According to the hex.pm, HTTPoison is the most popular HTTP client in Elixir. In fact, before Mint release, HTTPoison was the only Elixir/Erlang HTTP client which does proper SSL verification by default, out of the box. HTTPoison provides a simple and straightforward interface to send HTTP requests, hiding all the complexity of establishing a connection, maintaining a connection pool and so on.
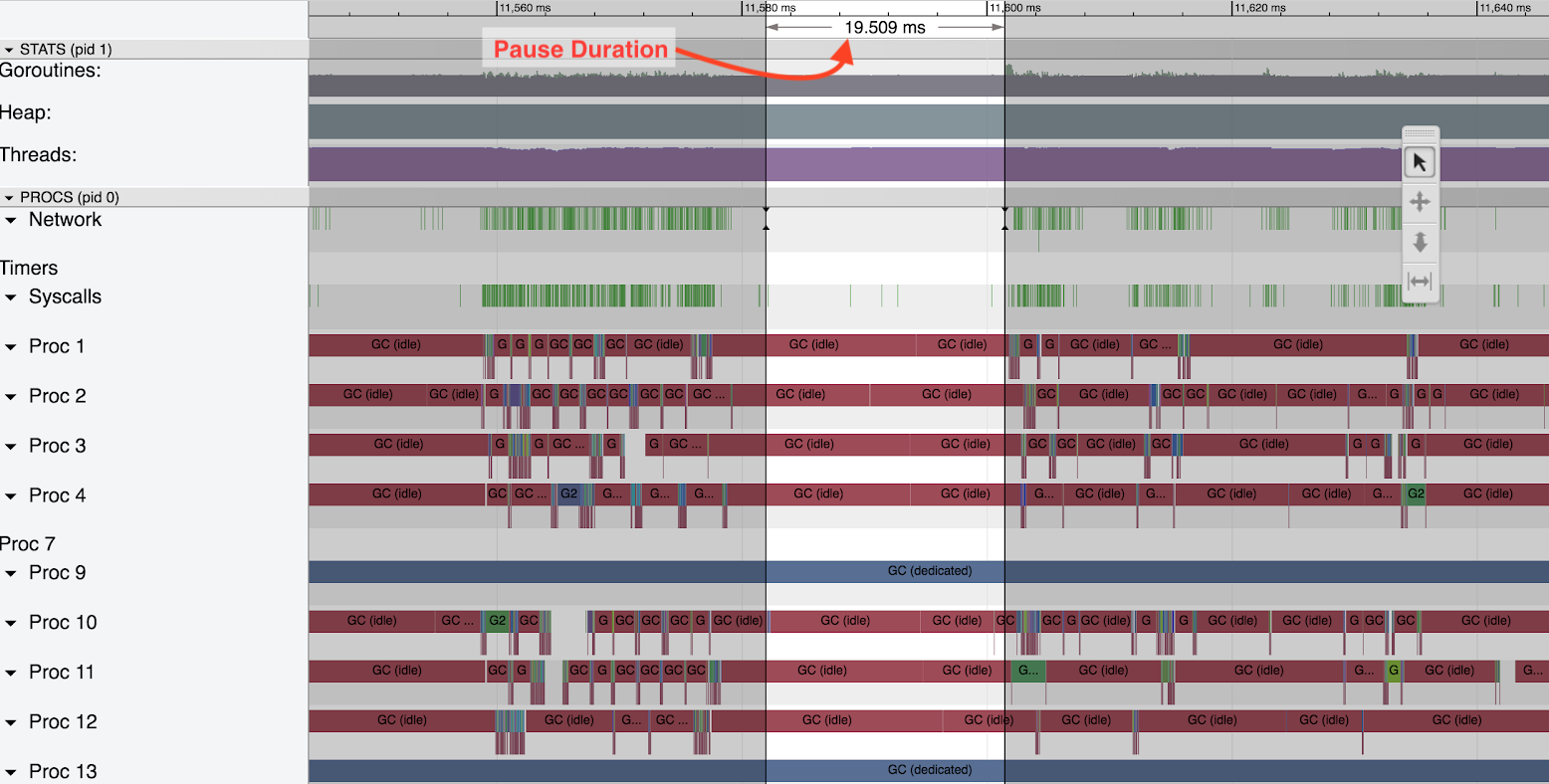
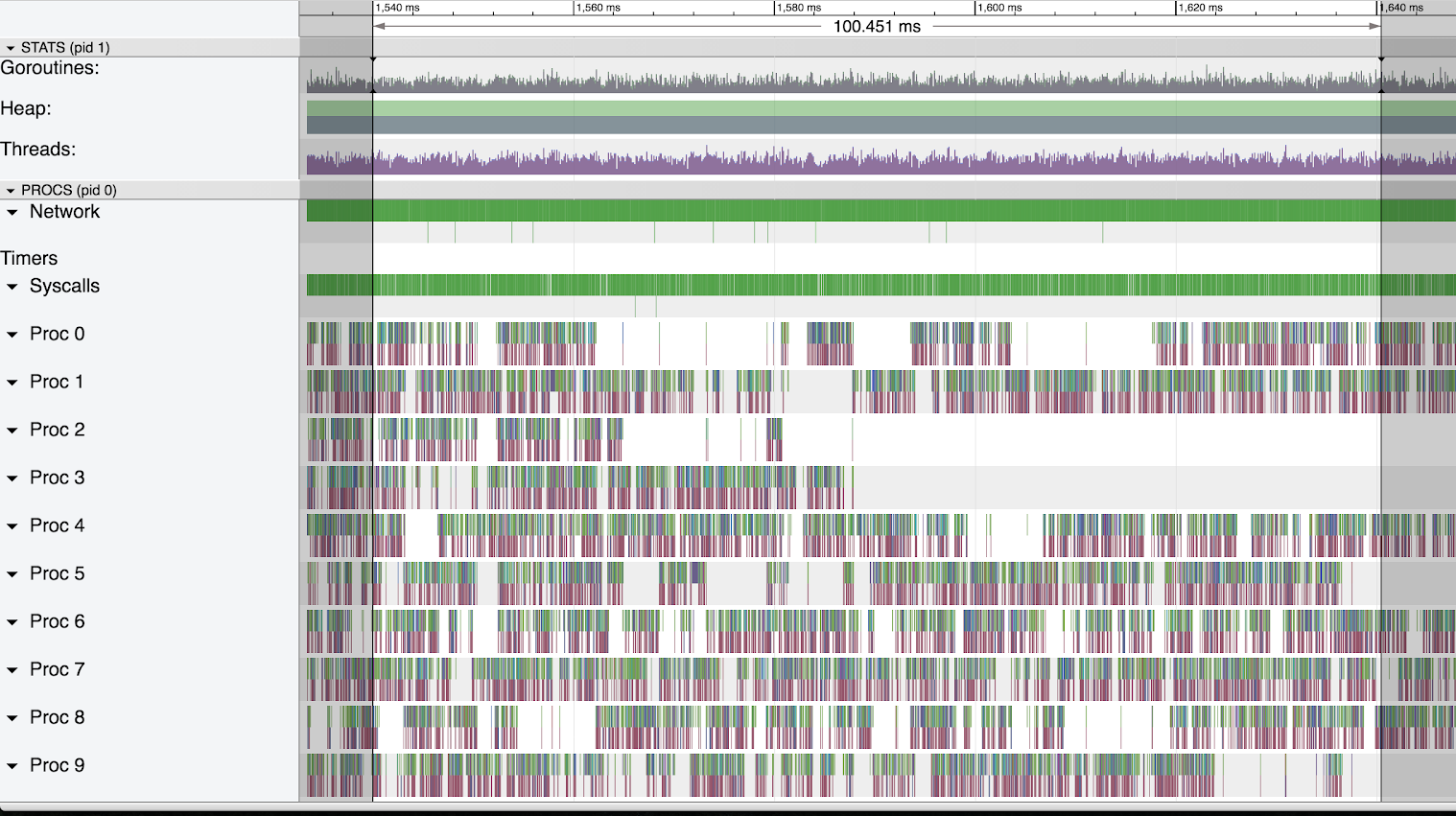
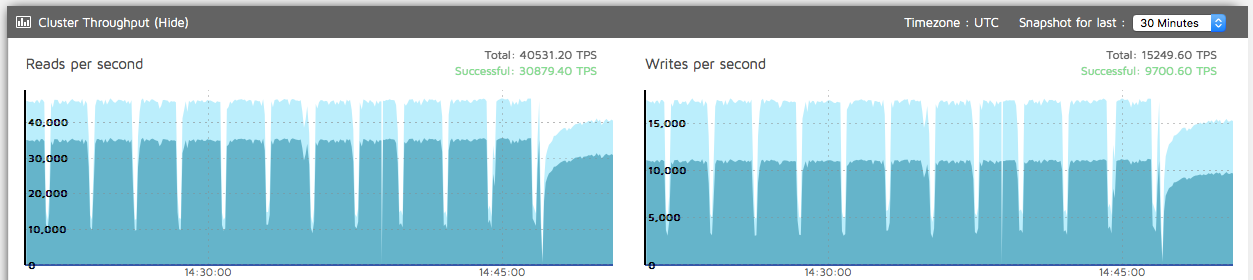
However, we’ve encountered some issues with hackney. Occasionally hackney could get stuck, so all the calls to HTTPoison would be hanging and blocking caller processes. It would look like on the graph below.
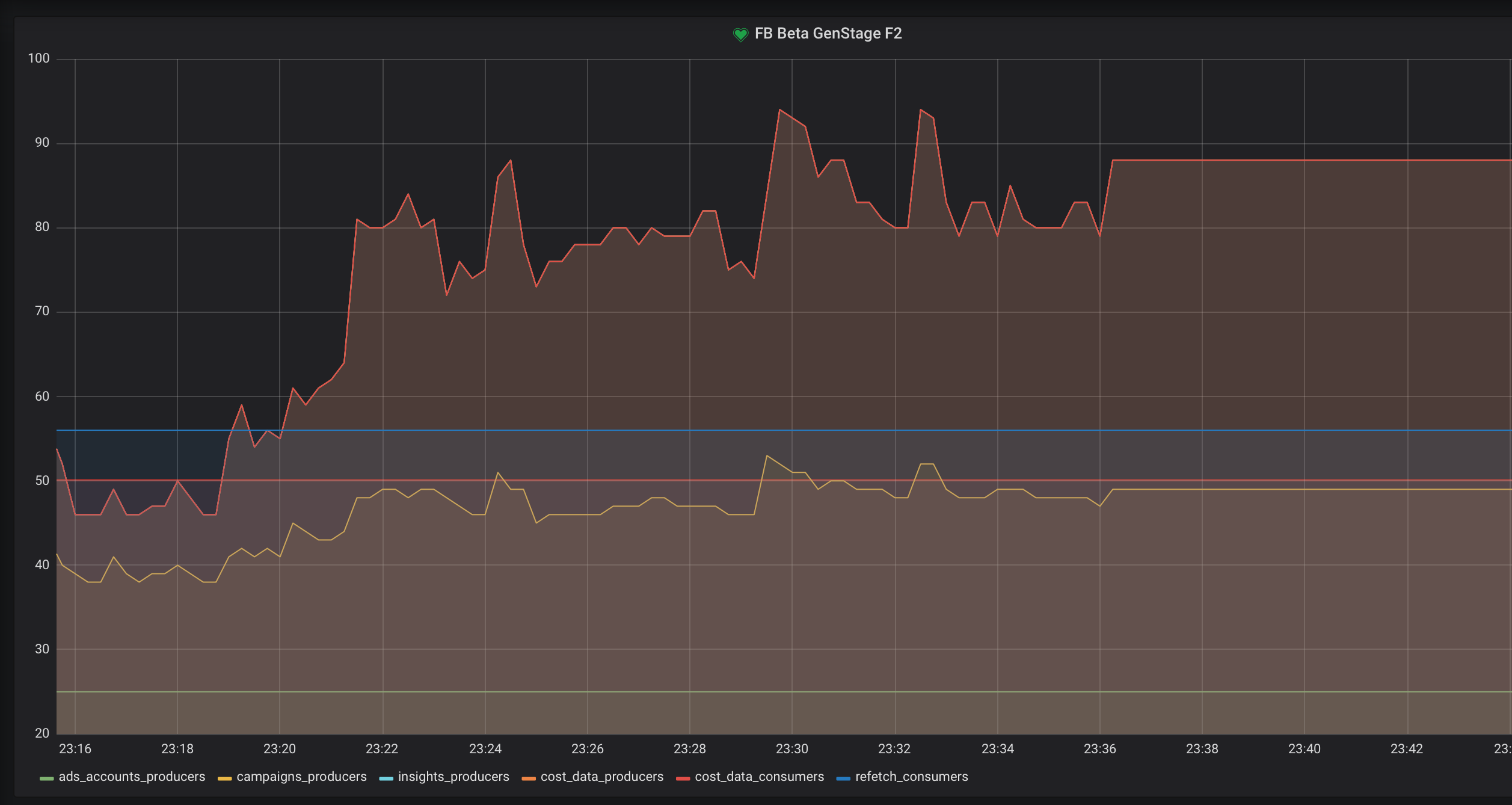
As you can see the new GenStage processes are not spawned anymore because all of the already spawned processes are blocked by the calls to HTTPoison. The only way to get out of this state was to restart hackney app using Application.stop/1 and Application.start/1 functions. Most likely the problems we’ve encountered are related to this issue.
Gun to the rescue
Thankfully by the time we started looking around for an alternative HTTP client, Gun reached 1.0.0 version. Gun is an Erlang HTTP library from the author of Cowboy. Gun provides low-level abstractions to work with the HTTP protocol. Every connection is a Gun process supervised by Gun’s Supervisor (gun_sup). A request is simply a message to a Gun process. A response is streamed back as messages to the process which initiated a connection. Full documentation could be found here. The asynchronous nature of Gun allows performing HTTP requests with multiple connections without locking a calling process. Gun does not provide a connection pool, so you should manage connections manually.
Here is how we implemented Gun based HttpClient module in our app.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
:gun.open/3 creates a new connection (a new gun process) to the given host and port. Once the process is started and a connection is established, gun process sends back a gun_up message which is caught by :gun.await_up/2. At this point, gun process is ready to receive requests.
We call HttpClient.connection/2 function upon CampaignProducer start because CampaignProducer is the first process in the GenStage pipeline which actually sends an HTTP request.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
This way CampaignsProducer is an owner of Gun process, so all it will receive are messages from Gun. Once CampaignProducer gets all the campaigns from Facebook, it passes them down the pipeline and spawns more GenStage workers which also send requests to Facebook. The idea here is that all the children GenStage processes would send subsequent requests to Facebook using this one connection created by CampaignProducer process. Thus the number of CampaignProducer across all Facebook accounts equals to the number of Gun workers/connections and it means we can control it. Let me show it on a scheme from the previous blog post.
+----------+ +----------+ +----------+
|Insights | |CostData | |CostData |
+---> |Producer <----+Producer <----+Consumer |
| | | |Consumer | | |
| +----------+ +----------+ +----------+
|
+------------+ +-----------+ +----------+ +----------+ +----------+
|Campaigns | |Campaigns | |Insights | |CostData | |CostData |
--|Producer <-----+Consumer +--> |Producer <----+Producer <----+Consumer |
| | |Supervisor | | | |Consumer | | |
+------------+ +-----------+ +----------+ +----------+ +----------+
|
| +----------+ +----------+ +----------+
| |Insights | |CostData | |CostData |
+---> |Producer <----+Producer <----+Consumer |
| | |Consumer | | |
+----------+ +----------+ +----------+
CampaignProducer initiates a new Gun connection, sends a request to Facebook to get campaigns and passes them down the pipeline. InsightsProducer and CostDataProducerConsumer use Gun’s connection they received from CampaignProducer and pass it to HttpClient’s get/2 and post/3 functions in order to send HTTP requests. It’s worth noting that sending a GET or POST request in this case does not spawn any new processes or connections. All the GenStage workers spawned by CampaignProducer send HTTP requests by utilizing the same Gun connection. When all campaigns are consumed, CampaignProducer closes Gun connection and dies with the normal state. Effectively, we’ve built a pool of Gun’s connections within the existing GenStage pipeline!
Let’s see how sending GET and POST requests with Gun would look like.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | |
That’s quite a lot of code. Gun’s documentation highlights it as well stating the advantages a developer has with such an architecture.
While it may seem verbose, using messages like this has the advantage of never locking your process, allowing you to easily debug your code. It also allows you to start more than one connection and concurrently perform queries on all of them at the same time.
Sending a request is basically sending a message to a Gun worker (conn_pid variable in our example). Then the process which initiated a connection starts to receive a response as messages from Gun process. A request is uniquely identified by stream_ref, so it’s important to pattern match against it in receive do block. Receiving the full response is achieved by receiving messages from Gun process till the :fin mark.
Please note, that the implementation above does block the process while the process is waiting for a message inside receive block. Having receive block was suffice for our case. In order to avoid any process locking, you should implement receive block via GenServer’s handle_info callbacks.
A word about SSL
As I mentioned above, HTTPoison is the only Elixir/Erlang library which does a proper SSL certificates verification by default. In order to instruct Gun to do so as well, you need to provide certain options to :gun.open/3 function.
1 2 3 4 5 6 7 8 9 10 11 | |
:certifi and :ssl_verify_hostname dependencies should be listed in your mix.exs.
Conclusion
Gun is a low-level HTTP client which is quite verbose and looks a bit awkward at first glance. However, it provides low-level abstractions to work with HTTP, giving you full control over connections and allowing you to receive responses asynchronously without locking your processes. And this is exactly what you need when you send millions of HTTP requests per day. The most important thing in our case was the ability to control connections and split them between different branches of GenStage pipeline. This way any single dropped connection does not impact others making our app resilent to HTTP errors.
P.S.
Recently two Elixir Core contributors @whatyouhide and @ericmj announced the first stable release of Mint, the very first native Elixir HTTP client. This is a big deal to Elixir community if you ask me. Mint does SSL verification by default and shares the same principles as Gun. However, while Mint has the same basic idea as Gun, the fundamental difference is that Mint is completely processless. Gun has Supervisor gun_sup which spawns Gun’s workers which hold connections. Every connection is a Gun process. Mint does not have that, a connection in Mint is just a struct. I’m looking forward to trying Mint in one of our projects in the future.
 Ferenc Erki is a core developer of Rex
and a system administrator at adjust,
where he is known as tamer of the ELK beast.
Ferenc Erki is a core developer of Rex
and a system administrator at adjust,
where he is known as tamer of the ELK beast.