
We recently had an opportunity to compare the garbage collection (GC) behaviour of a small Go application at different heap sizes. This application was built to migrate data away from a legacy datastore. The application contains an in-memory cache which can be configured to clear itself at different rates. This means we can look at the command during a GC cycle at various heap sizes and compare the impact of this on GC behaviour.
We found unexpected and severe whole system pauses during the garbage collector’s mark phase. This was an surprising, as Go widely advertises itself as having a low pause garbage collector. In particular we found that the expected ‘stop the world’ pause was very short, but that whole system pauses experienced during the mark phase were several orders of magnitude longer. Observing that these pauses exist is important for understanding why we see such a large performance impact from GC cycles when there are plenty of CPU resources available and the reported pauses are very short.
In this post we will detail what we saw during this experiment and discuss how this impacts the way we investigate GC performance for all of our systems going forward.
It is worth noting that the system measured here was compiled with Go version 1.10. As the GC algorithm is under constant development these effects may disappear in later releases.
Details On Tracing And Terminology
In order to compare the behaviour of this application (we will call it the MT command) we will be using the go trace tool. We will narrow our definition of system performance to the rate of ‘network events’. This is an attractive metric because it appears directly in the trace itself and because the MT command’s main behaviour is making requests to two datastores, so any disruption to the performance of the MT command should be reflected here.
Each trace is taken while forcing a GC cycle. This guarantees that we can trace the behaviour we are interested in.
Because the trace tool is primarily visual we will only perform a visual analysis. There are no statistics used to interpret any of these results. Being able to inspect the trace tool output numerically would be a valuable development.
We will look at the traces with three different heap sizes. The heap size is described by a range as the heap size is constantly fluctuating due to memory being allocated and GC cycles completed.
We will look at 3 different states of our running program, During GC, Stop The World Pause and Behaviour After GC. The system behaviour during GC is the most interesting, here we see unexpected, and unexpectedly long, whole system pauses.
During GC
8-13 GB Heap
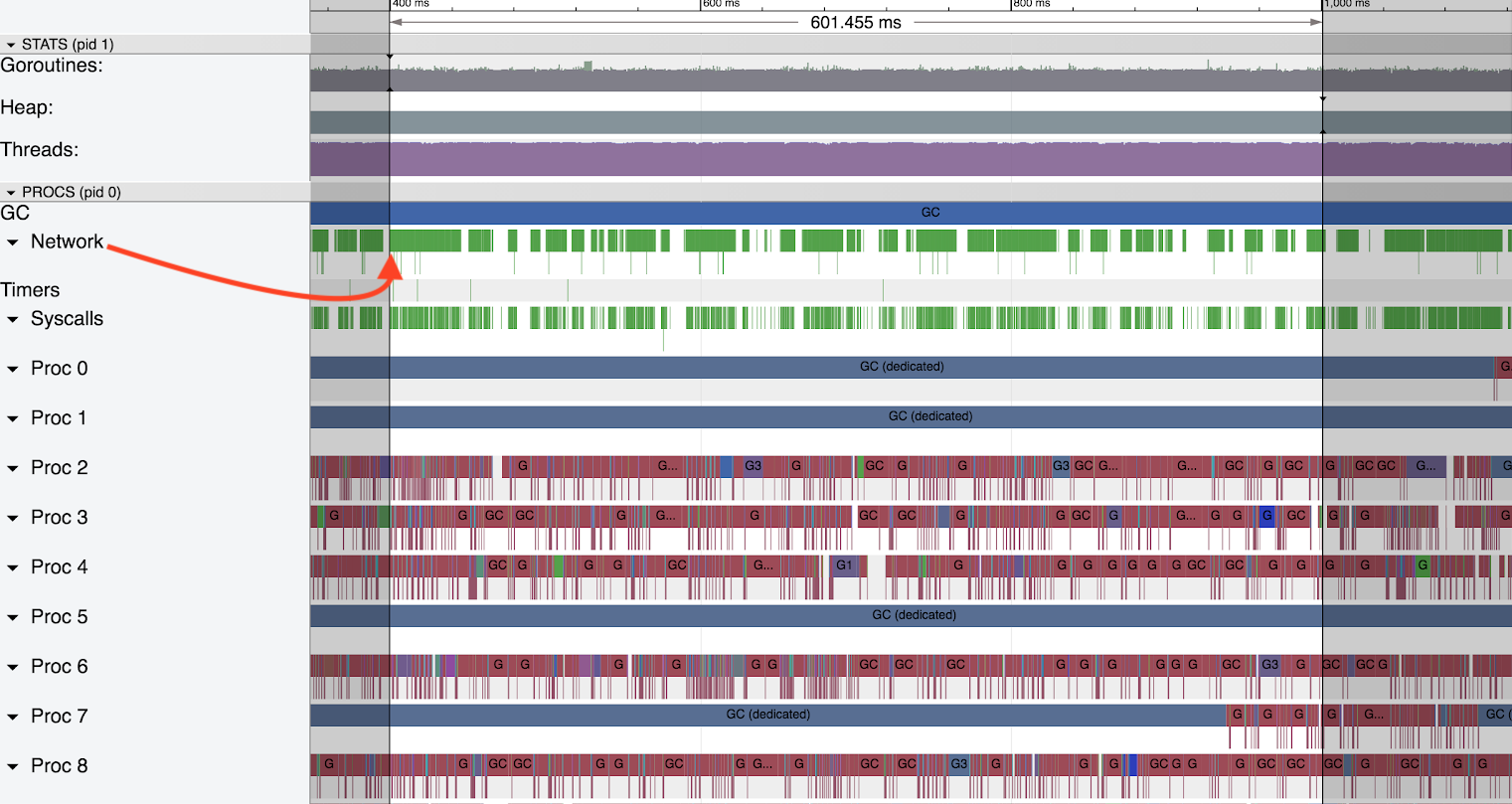
During GC the rate of network events (indicated by the red arrow) becomes very choppy, with frequent large blank gaps. Below the Network/Syscalls rows we saw three ‘Dedicated GC’ threads and a number of other threads which are a mix of Idle GC (dull red) and useful work (green and blue). Although not pictured here the remaining threads were dominated with Idle GC slices (here the word ‘slice’ refers to the period a goroutine was scheduled in a trace) with useful work being spread out across all threads.
20-30 GB Heap
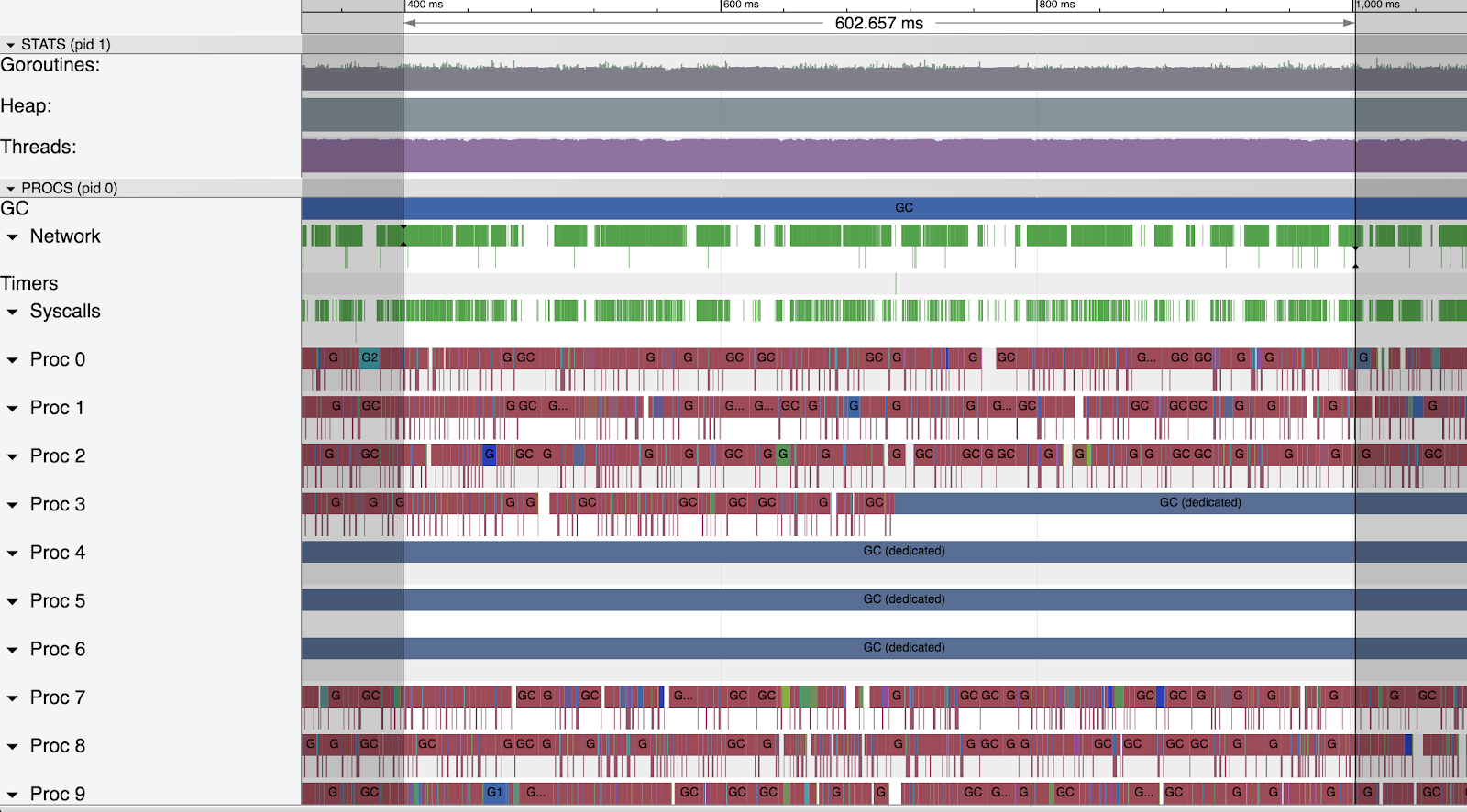
With a medium sized heap we saw a very similar trace during GC. Again we saw that the rate of network events is very choppy, with frequent large blank gaps.
60-70 GB Heap
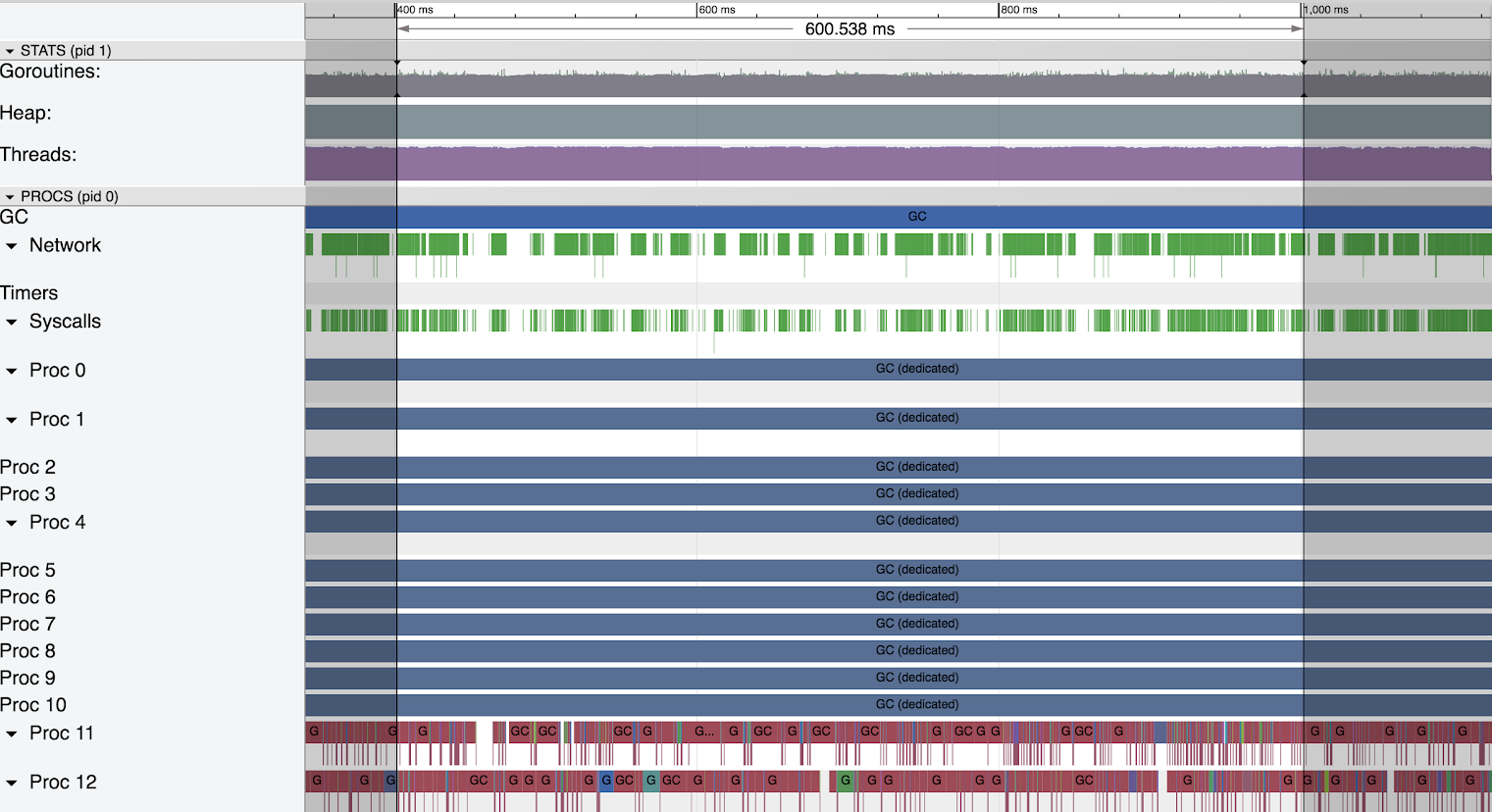
The largest heap size shows the same characteristic gaps as the previous smaller heaps.
A Single Unexpected Pause
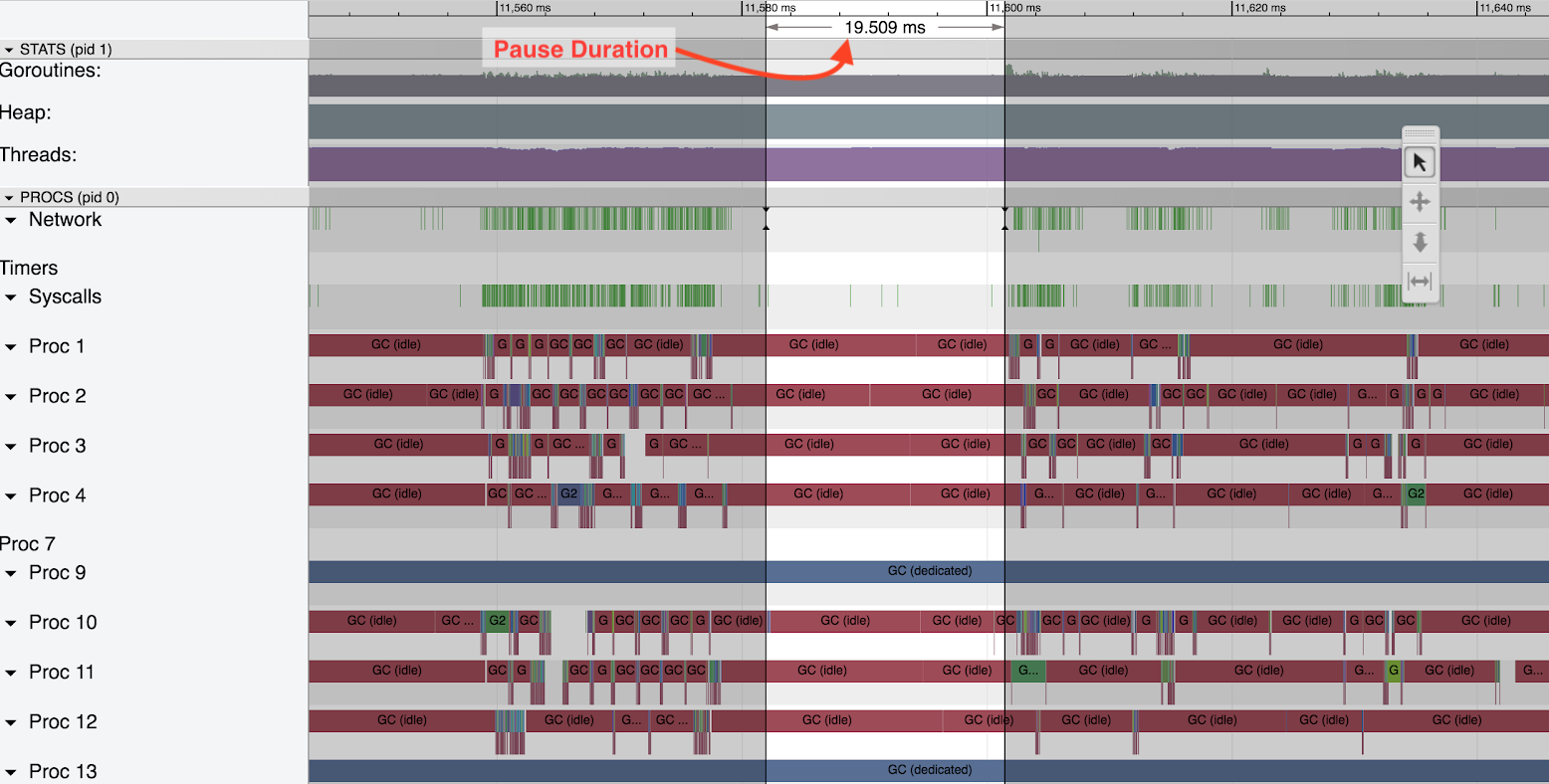
When we looked closely at the mark phase pauses we found that at each heap size they were of roughly similar size. Here we show one in detail. The ~19 millisecond pause (indicated by the red arrow) shown here shows how large these gaps can be. It should be noted that this gap was chosen because it was particularly large and probably indicates a rough worst case pause. But other gaps were much larger than 1 millisecond and very frequent.
Stop The World Pause
8-13 GB Heap
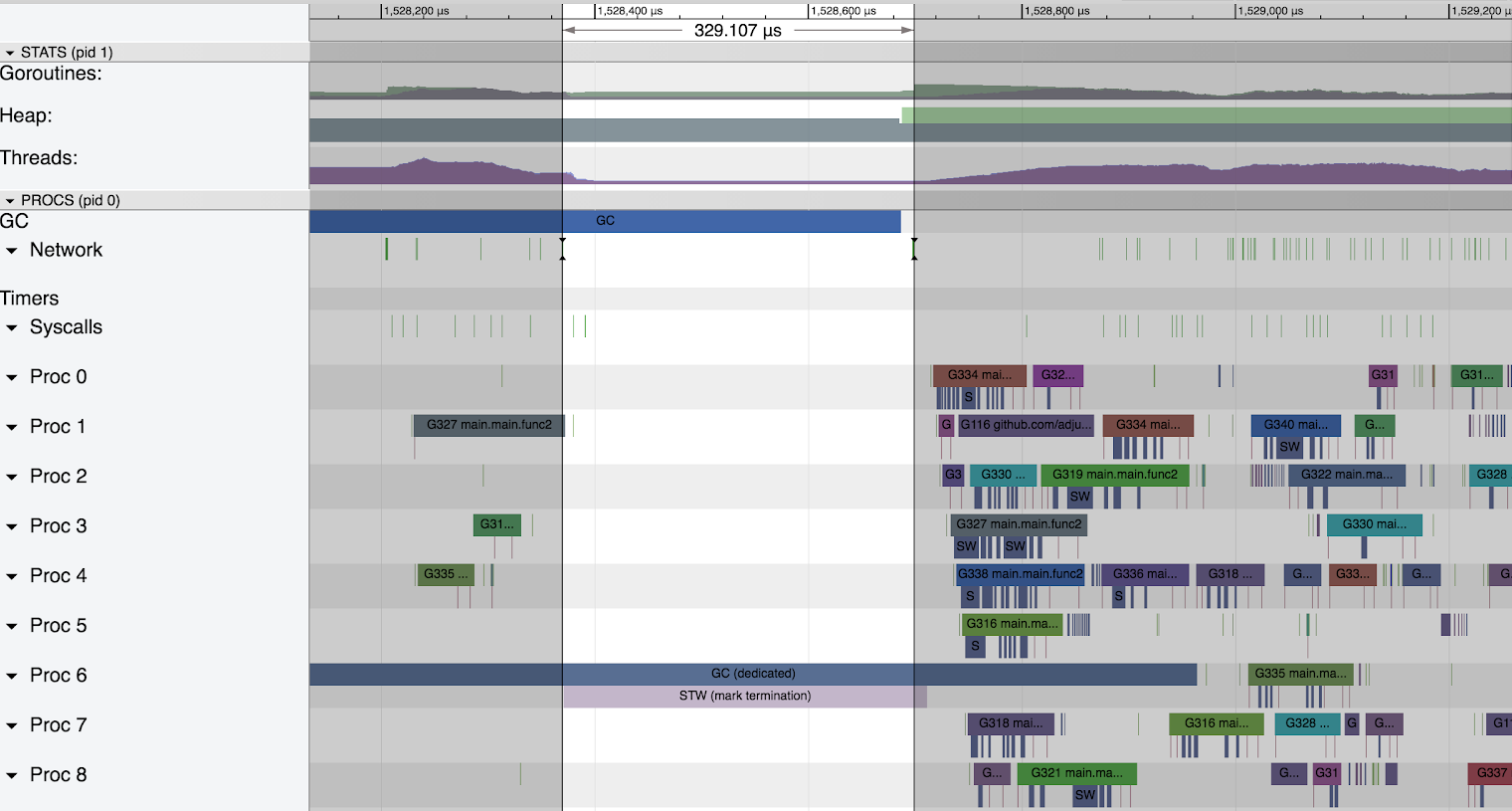
The final ‘stop the world’ pause is very short. Of a different order of magnitude compared to the pauses experienced during the mark phase above.
20-30 GB Heap
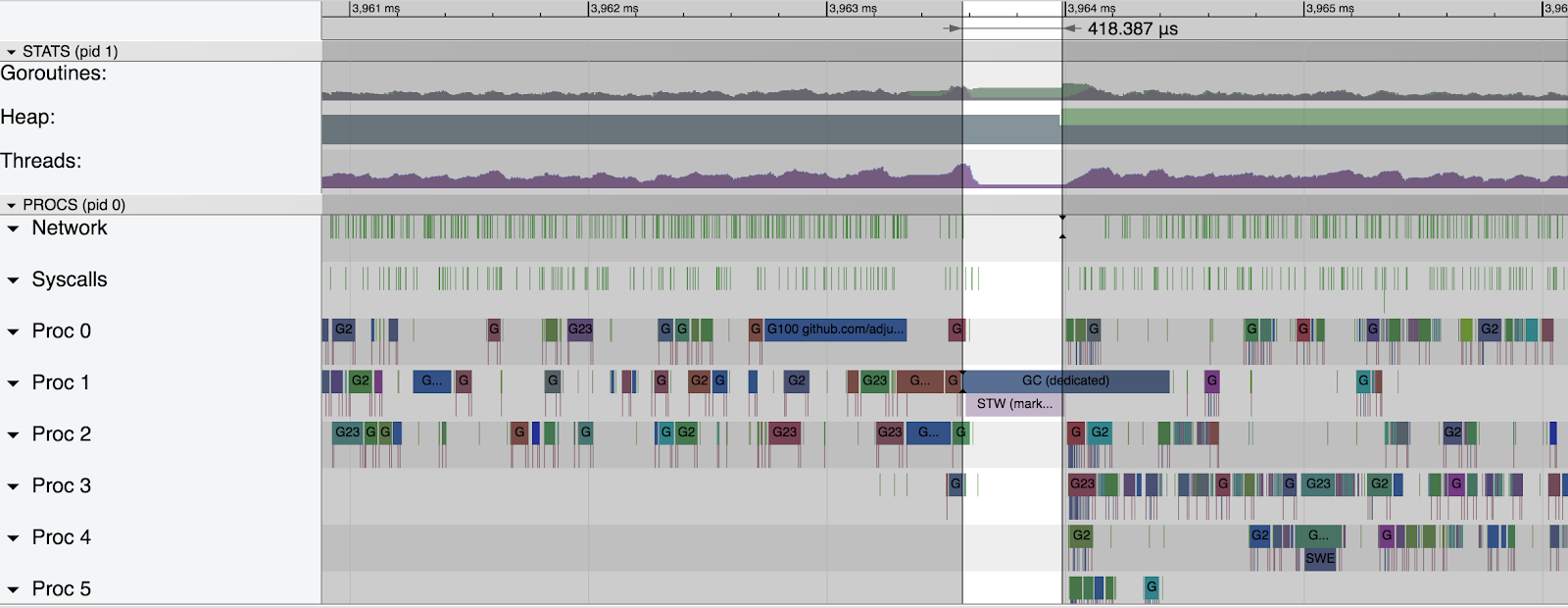
Another very short stop the world pause.
60-70 GB Heap
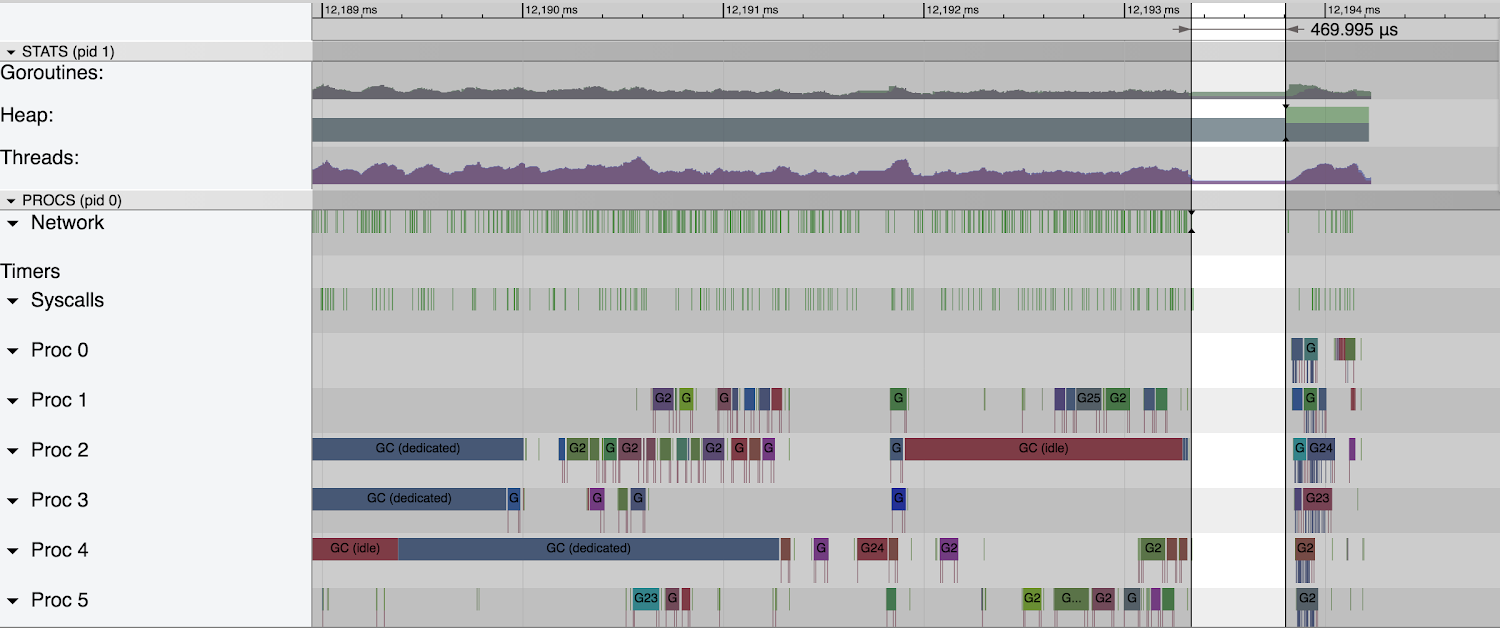
Here again the stop the world pause is very short. The pauses at the end of the mark phase was very short. As widely reported.
Normal System Performance
Here we compare the system performance outside of GC cycles at different heap sizes. We see no clear difference at different heap sizes, which is pretty much what you would expect.
8-12 GB Heap
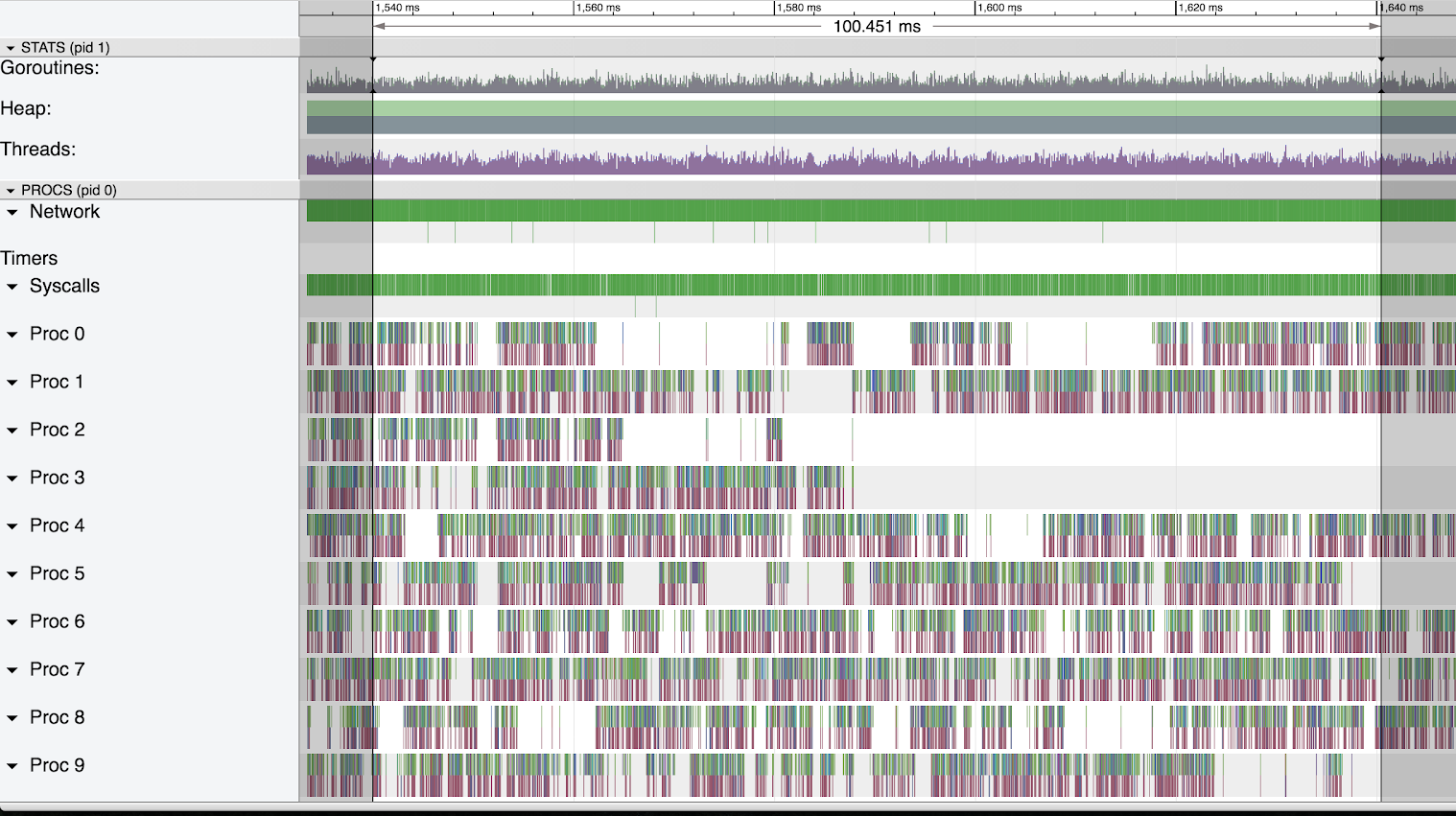
At the smallest heap size we saw a solid block of network events over a 100 millisecond period. Without GC running we get very constant performance with no large breaks in network events. Below the Network/Syscalls rows we saw the MT command running comfortably with many short running goroutine slices (top level green/blue slices) paired with syscalls (red slices just below).
20-30 GB Heap
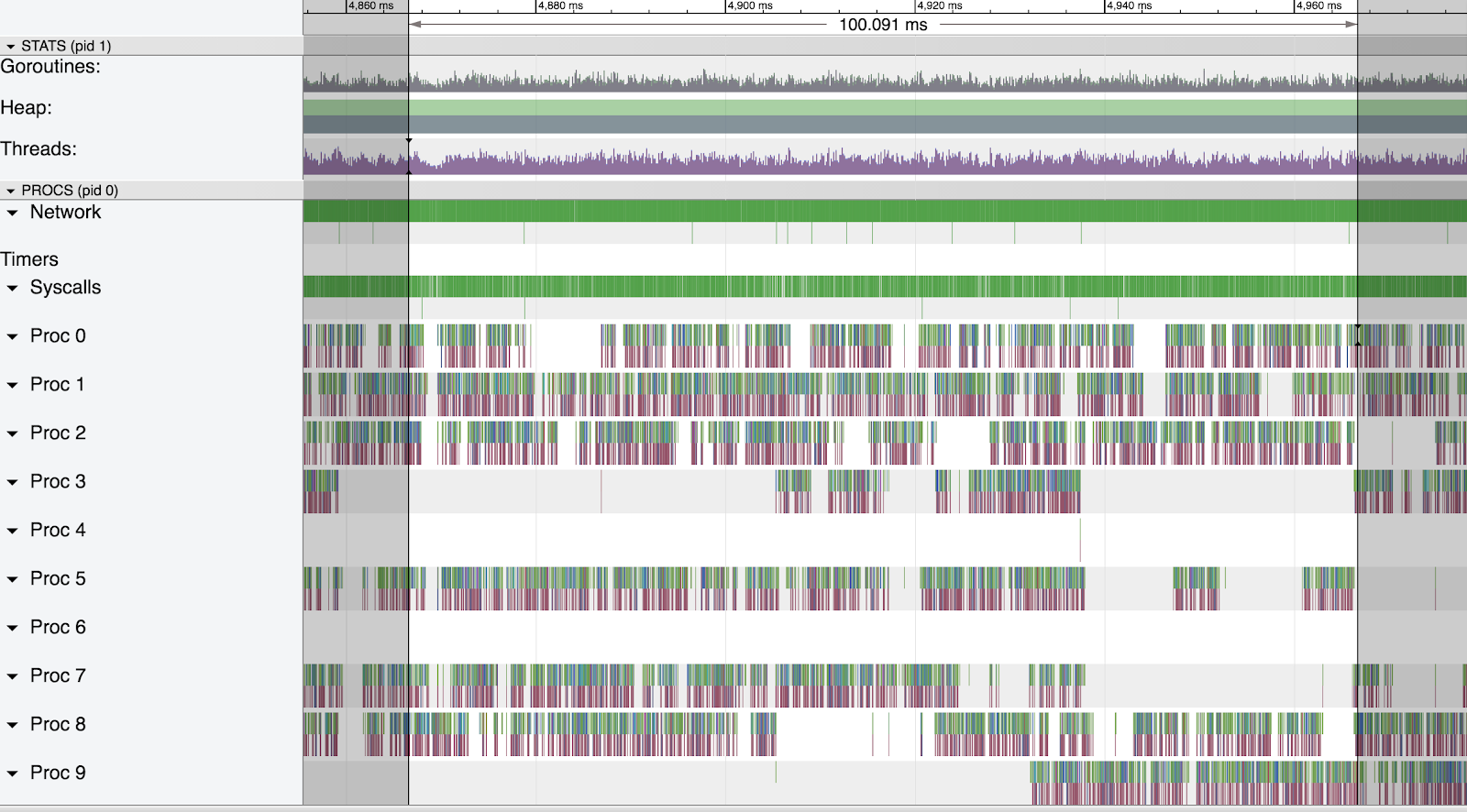
With a medium sized heap we saw the same behaviour.
95-105 GB Heap
With a 60-70 GB heap the GC cycle ran for almost 10 seconds and our trace only ran for 5 seconds so we didn’t capture any ‘after gc’ trace. We do have a GC-less trace when the heap ranged 95-105 GB. We will use that to observe the ‘normal’ behaviour with a very large heap.
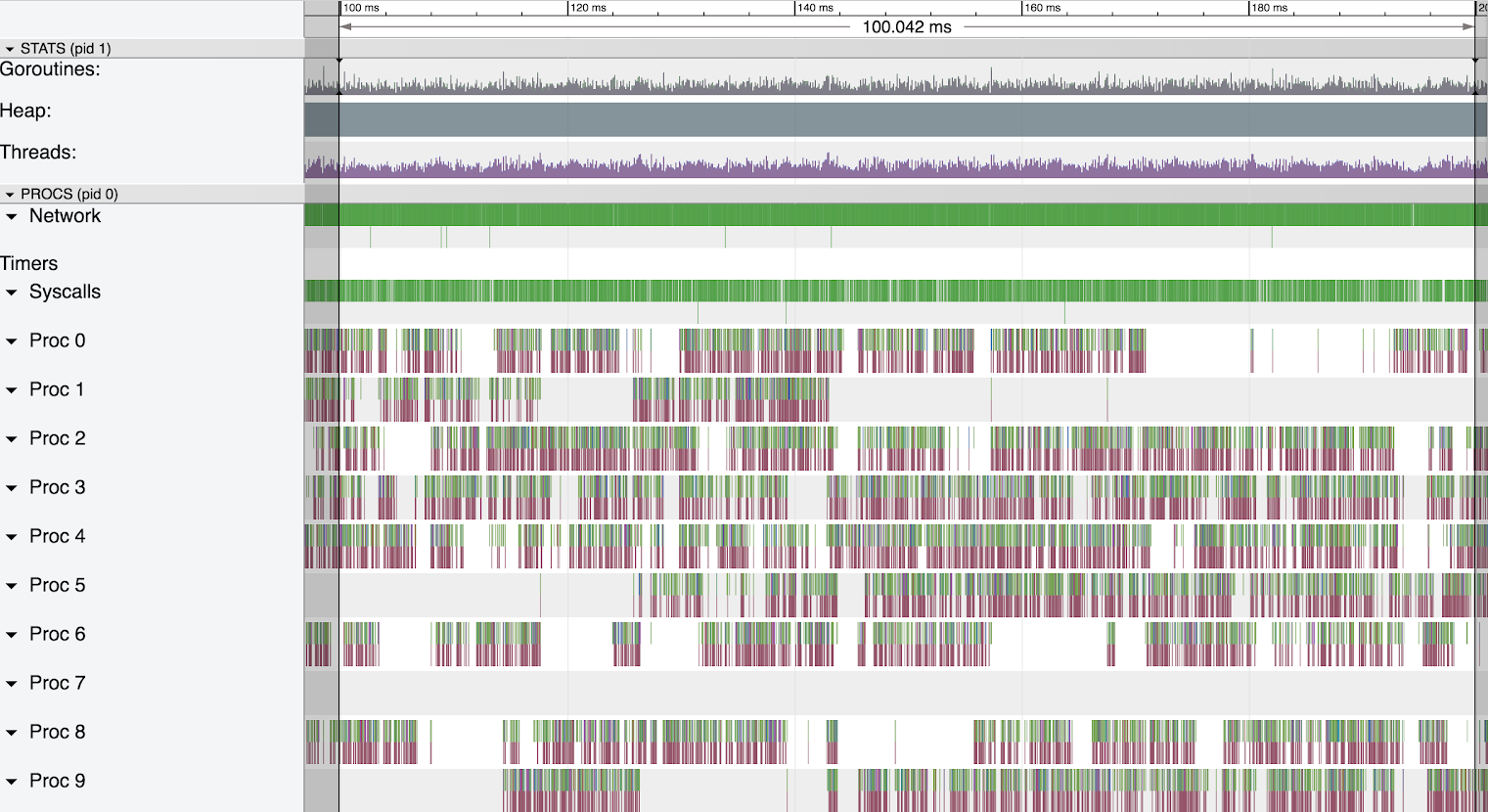
Even at this very large heap size we see the same normal system performance.
A ‘Normal’ Millisecond
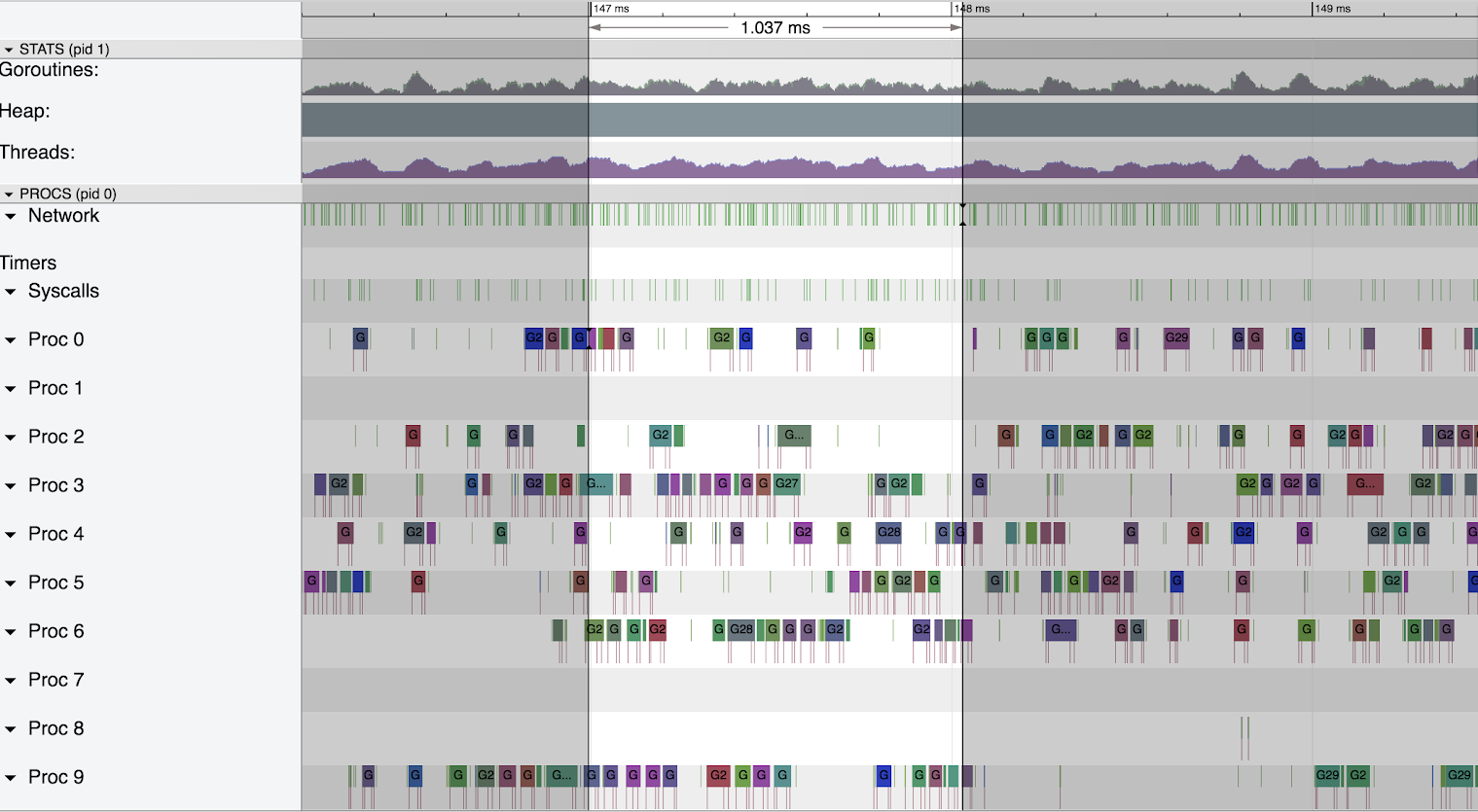
Here we zoom into a typical millisecond to get a feel for the normal rate of network events. Although we only present a sample from the 95-105 GB heap, the ‘normal’ rate of network events was very similar at all heap sizes we tested. It is interesting to relate this typical 1 millisecond period back to the large (up to ~20 millisecond) gaps we saw during GC. For every millisecond of pause we experience we are missing out on a very large number of network events.
External Systems
We have seen the impact of a GC cycle in the trace taken directly from the running MT command. But does it have any observable impact outside the command itself? If the impact was only visible in a detailed trace then we would not need to worry about these different behaviours. We can look at the metrics reported by one of the datastores to observe the increasing impact on performance as the heap grows.
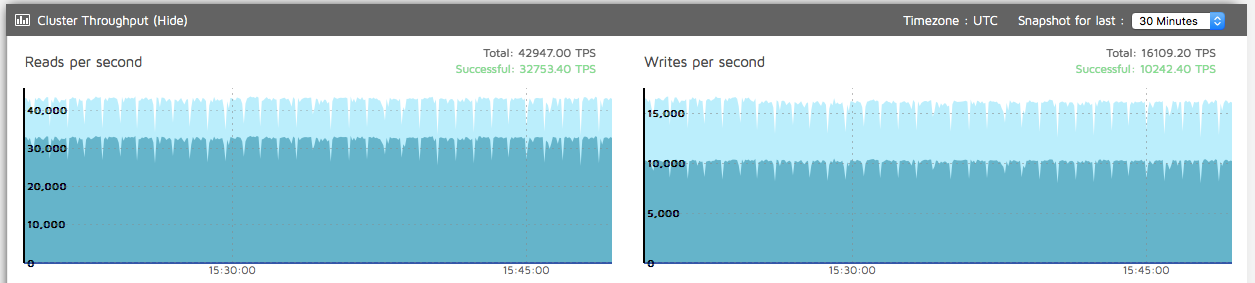
With a 8-15 GB heap we saw small shallow drops in read/write rates.
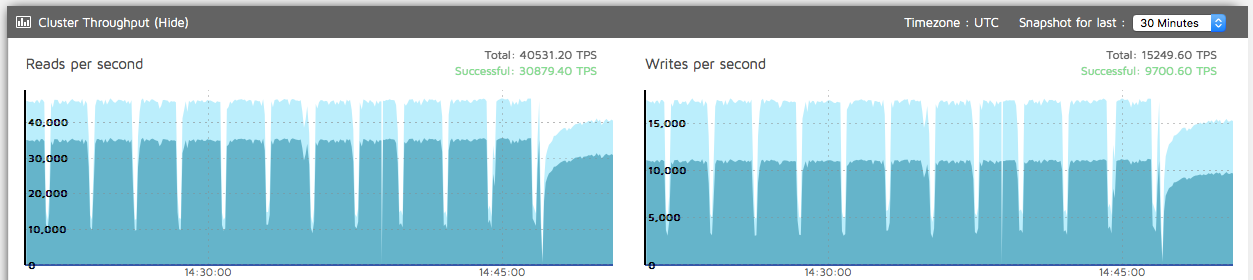
With a 98-107 GB heap we saw larger and deeper drops in read/write rates from the datastore’s perspective.
Conclusion
Go’s GC algorithm is advertised widely as having very low pauses. When people talk about GC pauses in Go applications they typically talk only about the ‘stop the world’ pause which occurs at the end of the mark phase. Our tests agree that this pause is very short, but we also experience clear and repeated pauses which are much larger than this during the mark phase. These pauses are much more interesting to us when trying to diagnose performance issues which may be GC related. Unfortunately these mark phase pauses are totally unreported by any of the standard metrics reported by the Go runtime and garbage collector.
The size of the mark pauses appear to be roughly similar at different heap sizes. The biggest impact heap sizes have is on the duration of the GC cycle itself. At 8-13 GB GC took 1.5 seconds to complete, at 20-30 GB GC took 4 seconds and at 60-70 GB heap GC took 12 seconds. This means that we experienced performance disruptions for longer periods the more the heap grew. It is particularly interesting to see a very large number of ‘Idle GC’ slices in each trace. The test was performed on a single machine with 48 cores. Execution without GC required roughly 2-4 cores, but with GOMAXPROCS unset the MT command could use all 48 cores. During GC it appears to try to use all available CPU cores, but most of them remain idle. The issue we see here could be the scheduler struggling to effectively schedule a very large number of non-performing GC goroutines.
If we want to understand the performance of Go systems with large heaps we cannot rely on the standard set of metrics. At this time we don’t know of any way to observe these performance degradations except by manually viewing traces, which is very awkward and time consuming. Further developments here would be very beneficial.