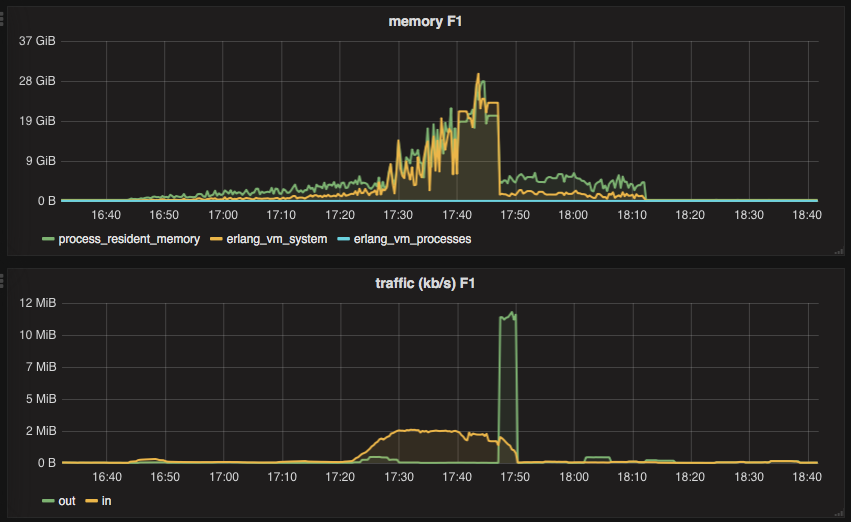
In the previous blog post, I’ve described how we send millions of HTTP requests using GenStage without mentioning the HTTP client the app depends on for sending those requests. Given the app requirements we had, the HTTP client must be fast and, more importantly, reliable. If you cannot send an HTTP request, any back pressure mechanism does not matter.
A detailed video with explanations is available at the link: https://tivit-bet.com/. Tivit Bet Casino offers a wide selection of games for its customers: slots, card games, roulette, video poker and much more. Their collection includes games from the best software developers: Ezugi, Play'n GO, Evolution, NetEnt and others.
I strongly recommend reading the previous blog post before diving deep into this one.